

В современном бизнесе данные — это стратегический актив. Компании хотят быть уверены, что их аналитика основана на полной, достоверной и прозрачной информации. Но традиционные подходы к построению хранилищ данных часто оказываются слишком негибкими и плохо справляются с изменениями источников или бизнес-правил.
На этом фоне появился Data Vault — методология, которая соединяет в себе преимущества гибкой архитектуры, детальной истории изменений и высокой масштабируемости.
Команда Conteq имеет широкий опыт работы с Data Vault, поэтому в нашей статье мы расскажем не только о том, что из себя представляет эта методология для тех, кто еще не знаком с ней, но и подробнее — о практике наших специалистов.
На этом фоне появился Data Vault — методология, которая соединяет в себе преимущества гибкой архитектуры, детальной истории изменений и высокой масштабируемости.
Команда Conteq имеет широкий опыт работы с Data Vault, поэтому в нашей статье мы расскажем не только о том, что из себя представляет эта методология для тех, кто еще не знаком с ней, но и подробнее — о практике наших специалистов.
Что такое Data Vault
Data Vault — это методология проектирования хранилища данных, предложенная Дэном Линстедом, цель которой — обеспечить долговечность и устойчивость архитектуры при постоянных изменениях в источниках данных и бизнес-процессах.
В основе Data Vault лежит простая структура:
Такое разделение позволяет максимально четко разграничить: что стабильно (бизнес-ключи), что изменчиво (атрибуты), и как это связано (связи).
В основе Data Vault лежит простая структура:
- Hubs (Хабы) — центральные таблицы, где хранятся бизнес-ключи (например, идентификаторы клиентов, заказов, счетов).
- Links (Связи) — таблицы, которые фиксируют отношения между хабами (например, «клиент сделал заказ»).
- Satellites (Спутники) — таблицы, содержащие описательные атрибуты и их историю изменений (например, имя клиента, адрес, статус заказа).
Такое разделение позволяет максимально четко разграничить: что стабильно (бизнес-ключи), что изменчиво (атрибуты), и как это связано (связи).
Data Vault 2.0: шаг вперед
На практике мы в Conteq используем именно Data Vault 2.0. Это обновленная версия методологии, которая учитывает актуальные вызовы эпохи Big Data и облачных платформ.
Главное отличие от версии 1.0 — использование хеш-ключей вместо последовательных идентификаторов. Это позволило перейти к параллельной загрузке хабов, ссылок и сателлитов, повысить масштабируемость и гибкость. Дополнительно DV 2.0 делает акцент на бизнес-ключах и вводит стандарты моделирования, загрузки и документирования.
Data Vault 1.0, созданный Дэном Линстедтом в конце 1990-х, базировался на архитектуре hub-and-spoke. В 2013 году Линстедт совместно с Майклом Ольшимке представили Data Vault 2.0, который сохранил эту основу, но добавил новые уровни:
Таким образом, DV превратился из новой модели данных в полноценную архитектуру корпоративной аналитики, который можно охарактеризовать как гибридный подход, сочетающий в себе преимущества третьей нормальной формы (3NF) и схемы «звезда».
Главное отличие от версии 1.0 — использование хеш-ключей вместо последовательных идентификаторов. Это позволило перейти к параллельной загрузке хабов, ссылок и сателлитов, повысить масштабируемость и гибкость. Дополнительно DV 2.0 делает акцент на бизнес-ключах и вводит стандарты моделирования, загрузки и документирования.
Data Vault 1.0, созданный Дэном Линстедтом в конце 1990-х, базировался на архитектуре hub-and-spoke. В 2013 году Линстедт совместно с Майклом Ольшимке представили Data Vault 2.0, который сохранил эту основу, но добавил новые уровни:
- Raw Vault — хранение «сырых» данных;
- Business Vault — слой бизнес-правил и преобразований;
- Data Mart — аналитический слой для отчетов и визуализаций.
Таким образом, DV превратился из новой модели данных в полноценную архитектуру корпоративной аналитики, который можно охарактеризовать как гибридный подход, сочетающий в себе преимущества третьей нормальной формы (3NF) и схемы «звезда».
Подытожим ключевые особенности DV 2.0:
Данные никогда не обновляются и не удаляются, а только добавляются в виде новых записей — это обеспечивает полную историчность благодаря тому, что вся история изменений каждого атрибута сохраняется. «Опоздавшие» записи из источников добавляются без проблем и могут быть корректно учтены в аналитике при построении снимков данных на нужную дату, значительно повышая производительность.
Архитектура позволяет легко и безболезненно интегрировать новые источники данных и бизнес-сущности. Это достигается за счет разделения структур (Хабы, Линки, Сателлиты) и изоляции изменений. Модель не требует постоянной перестройки, что поддерживает высокий темп развития (Agile).
По мнению одного из главных популяризаторов Data Vault 2.0, Патрика Кьюбы (Patrick Cuba), одно из ключевых преимуществ новой версии — корректная обработка временных аномалий, таких как «time crime» (некорректные временные метки из источников). Для этого используются специализированные конструкции:
- Принцип «Только вставка» (Insert-Only)
Данные никогда не обновляются и не удаляются, а только добавляются в виде новых записей — это обеспечивает полную историчность благодаря тому, что вся история изменений каждого атрибута сохраняется. «Опоздавшие» записи из источников добавляются без проблем и могут быть корректно учтены в аналитике при построении снимков данных на нужную дату, значительно повышая производительность.
- Гибкость и масштабируемость
Архитектура позволяет легко и безболезненно интегрировать новые источники данных и бизнес-сущности. Это достигается за счет разделения структур (Хабы, Линки, Сателлиты) и изоляции изменений. Модель не требует постоянной перестройки, что поддерживает высокий темп развития (Agile).
- Мощный механизм работы со временем
По мнению одного из главных популяризаторов Data Vault 2.0, Патрика Кьюбы (Patrick Cuba), одно из ключевых преимуществ новой версии — корректная обработка временных аномалий, таких как «time crime» (некорректные временные метки из источников). Для этого используются специализированные конструкции:
- Satellites for Record Tracking (RTS): отслеживают источник и системные метки времени загрузки.
- Satellites for Record Tracking eXtended (XTS): расширяют RTS, позволяя фиксировать несколько временных меток из самой бизнес-транзакции (например, время заказа и время отгрузки), что позволяет автоматически выстраивать корректные временные линии и избегать искажений в аналитических отчетах.
Недостатки Data Vault
Главные недостатки Data Vault связаны с его сложностью: большое количество таблиц и связей делает модель трудной для реализации и сопровождения, особенно это касается новичков. Data Vault требует обширной документации, как и любая архитектура данных. Документация необходима для понимания структуры «хабов», «ссылок» и «сателлитов», связей между ними, бизнес-правил, а также для управления изменениями и обеспечения целостности данных. Для составления аналитических запросов требуется множество JOIN-операций, что может снижать производительность по сравнению с денормализованными схемами, где данные намеренно дублируются и объединяются в более крупные таблицы для ускорения запросов, жертвуя при этом некоторой целостностью данных в пользу повышения производительности чтения.
Альтернативные подходы к моделированию хранилищ данных
Хотя Data Vault набирает популярность благодаря своей масштабируемости и прозрачности, это далеко не единственная методология построения корпоративных хранилищ данных. В разных компаниях и проектах применяются и другие подходы, выбор которых зависит от задач бизнеса, скорости изменений и требований к качеству данных.
1. Inmon (Corporate Information Factory)
Билл Инмон считается «отцом» концепции хранилищ данных. Его подход предполагает построение Enterprise Data Warehouse (EDW) в нормализованной форме (3NF).
В сравнении с Data Vault: Inmon более строгий и менее гибкий. Data Vault часто рассматривают как «мост» между философией Инмона и реальными вызовами изменений.
2. Kimball (Dimensional Modeling)
Ральф Кимбалл предложил модель «звезды» (Star Schema), ориентированную на удобство бизнес-аналитиков.
В сравнении с Data Vault: Kimball проще на старте, но хуже масштабируется и поддерживает историю. Поэтому Data Vault часто используют как слой интеграции, а «звезду» — как слой представления (Data Mart).
3. Anchor Modeling
Anchor Modeling — более современный метод, близкий по духу к Data Vault. Он тоже строится вокруг «якорей» (аналог хабов) и атрибутов, но дополнительно использует высокую нормализацию и «темпоральность» (историчность данных).
В сравнении с Data Vault: Anchor считается более академичным и теоретически изящным, но Data Vault практичнее и лучше поддерживается индустрией.
4. Data Lake + Schema-on-Read
Современный тренд — собирать все данные в Data Lake (например, на Hadoop, S3 или Delta Lake), а структуру накладывать при чтении.
В сравнении с Data Vault: Data Lake быстрее и дешевле на старте, но не решает задачи интеграции и качества данных. В практике мы часто видим гибрид: Data Lake для «сырых» данных и Data Vault для управляемого слоя интеграции.
5. Data Mesh
Data Mesh — это не столько модель данных, сколько организационная философия: ответственность за данные распределяется между доменными командами.
В сравнении с Data Vault: Mesh может использовать Data Vault как один из инструментов. То есть DV решает задачу интеграции и хранения, а Mesh — организационную модель владения данными.
1. Inmon (Corporate Information Factory)
Билл Инмон считается «отцом» концепции хранилищ данных. Его подход предполагает построение Enterprise Data Warehouse (EDW) в нормализованной форме (3NF).
- Плюсы: строгая структура, единый источник правды, хорошо подходит для аналитики на уровне предприятия.
- Минусы: сложно адаптировать к изменениям бизнес-процессов, дорого и долго строить.
В сравнении с Data Vault: Inmon более строгий и менее гибкий. Data Vault часто рассматривают как «мост» между философией Инмона и реальными вызовами изменений.
2. Kimball (Dimensional Modeling)
Ральф Кимбалл предложил модель «звезды» (Star Schema), ориентированную на удобство бизнес-аналитиков.
- Плюсы: простота, высокая производительность запросов, удобство для BI-инструментов.
- Минусы: плохо справляется с изменениями источников, требует много ручной работы по интеграции данных.
В сравнении с Data Vault: Kimball проще на старте, но хуже масштабируется и поддерживает историю. Поэтому Data Vault часто используют как слой интеграции, а «звезду» — как слой представления (Data Mart).
3. Anchor Modeling
Anchor Modeling — более современный метод, близкий по духу к Data Vault. Он тоже строится вокруг «якорей» (аналог хабов) и атрибутов, но дополнительно использует высокую нормализацию и «темпоральность» (историчность данных).
- Плюсы: гибкость, компактность модели, встроенное управление временем.
- Минусы: менее распространен, меньше инструментов и специалистов.
В сравнении с Data Vault: Anchor считается более академичным и теоретически изящным, но Data Vault практичнее и лучше поддерживается индустрией.
4. Data Lake + Schema-on-Read
Современный тренд — собирать все данные в Data Lake (например, на Hadoop, S3 или Delta Lake), а структуру накладывать при чтении.
- Плюсы: низкая стоимость хранения, высокая скорость подключения новых источников.
- Минусы: хаос в данных, слабая управляемость, проблемы с качеством и историчностью.
В сравнении с Data Vault: Data Lake быстрее и дешевле на старте, но не решает задачи интеграции и качества данных. В практике мы часто видим гибрид: Data Lake для «сырых» данных и Data Vault для управляемого слоя интеграции.
5. Data Mesh
Data Mesh — это не столько модель данных, сколько организационная философия: ответственность за данные распределяется между доменными командами.
- Плюсы: децентрализация, гибкость, подходит для больших организаций с сильной продуктовой культурой.
- Минусы: сложно внедрить, требует зрелости процессов и культуры работы с данными.
В сравнении с Data Vault: Mesh может использовать Data Vault как один из инструментов. То есть DV решает задачу интеграции и хранения, а Mesh — организационную модель владения данными.
Как выбрать?
- Если нужен быстрый старт и простая отчетность → Kimball.
- Если требуется единое корпоративное хранилище с жесткой структурой → Inmon.
- Если проект инновационный и важна темпоральность → Anchor Modeling.
- Если нужен дешевый и гибкий «склад сырых данных» → Data Lake.
- Если компания большая и готова к распределенному владению данными → Data Mesh.
- Если нужен баланс между историчностью, гибкостью и практичностью → Data Vault 2.0.
Пример Data Vault
Data Vault идеально подходит для таких сценариев, где важна гибкость, аудируемость и адаптивность к изменениям.
В качестве примера рассмотрим модель Data Vault для системы "Клиенты - Счета - Транзакции".
В качестве примера рассмотрим модель Data Vault для системы "Клиенты - Счета - Транзакции".
Хабы (Hubs) - Списки уникальных бизнес-ключей
Хранят список всех уникальных сущностей системы. Это основа модели.
Hub_Customer
Hub_Account
Hub_Transaction
Hub_Customer
- HK_Customer_ID (Primary Key, Hash от бизнес-ключа)
- Customer_ID (Бизнес-ключ, например, CUST-12 345)
- Load_DTS (Метка времени загрузки записи)
- Record_Source (Источник данных, например, CRM_SYSTEM_APP)
Hub_Account
- HK_Account_ID (Primary Key, Hash от бизнес-ключа)
- Account_ID (Бизнес-ключ, например, ACC-67 890)
- Load_DTS
- Record_Source
Hub_Transaction
- HK_Transaction_ID (Primary Key, Hash от бизнес-ключа)
- Transaction_ID (Бизнес-ключ, например, TXN-98 765)
- Load_DTS
- Record_Source
Линки (Links) - Связи между хабами
Описывают транзакционные связи или связи "многие-ко-многим" между сущностями.
Link_Customer_Account (Связь "Клиент владеет Счетом")
Link_Account_Transaction (Связь "На Счете совершена Транзакция")
Link_Customer_Account (Связь "Клиент владеет Счетом")
- LK_Customer_Account_ID (Primary Key, Hash от HK_Customer_ID + HK_Account_ID)
- HK_Customer_ID (FK на Hub_Customer)
- HK_Account_ID (FK на Hub_Account)
- Load_DTS
- Record_Source
Link_Account_Transaction (Связь "На Счете совершена Транзакция")
- LK_Account_Transaction_ID (Primary Key, Hash от HK_Account_ID + HK_Transaction_ID)
- HK_Account_ID (FK на Hub_Account)
- HK_Transaction_ID (FK на Hub_Transaction)
- Load_DTS
- Record_Source
Сателлиты (Satellites) - Контекст и атрибуты
Хранят всю описательную информацию, исторические изменения атрибутов.
Sat_Customer_Details (Детали клиента)
Sat_Account_Details (Детали счета)
Sat_Transaction_Details (Детали транзакции)
Допустим, клиент Иван Иванов открыл счет и совершил первую транзакцию.
- HK_Customer_ID (FK на Hub_Customer, часть PK)
- Load_DTS (Метка времени, часть PK)
- Hash_Diff (Хэш от всех атрибутов для отслеживания изменений)
- Load_End_DTS (Метка времени, когда версия перестала быть актуальной)
- Record_Source
- FirstName
- LastName
- DateOfBirth
Sat_Account_Details (Детали счета)
- HK_Account_ID (FK на Hub_Account, часть PK)
- Load_DTS
- Hash_Diff
- Load_End_DTS
- Record_Source
- Account_Type (e.g., "дебетовый", "кредитный", "сберегательный")
- Currency_Code (e.g., "RUB", "USD")
- Open_Date
- Status (e.g., "активный", "закрытый")
Sat_Transaction_Details (Детали транзакции)
- HK_Transaction_ID (FK на Hub_Transaction, часть PK)
- Load_DTS
- Hash_Diff
- Load_End_DTS
- Record_Source
- Transaction_Type (e.g., "пополнение", "списание", "перевод")
- Amount
- Transaction_Date
- Merchant_Info
Допустим, клиент Иван Иванов открыл счет и совершил первую транзакцию.
Практика Conteq
В одном из наших проектов мы применили Data Vault 2.0 для интеграции данных из различных систем-источников в компании Заказчика — одной из крупнейших энергосбытовых компаний России. Клиент обратился к нам с проблемой — невозможность регулярной и своевременной обработки объемов данных и затрудненный доступ сотрудников к оперативной информации. Классическая модель искажала историю, что влияло на аналитические отчеты.
В ходе проекта мы реализовали корпоративное хранилище данных на методологии Data Vault 2.0 и смогли обеспечить динамическую поддержку различных отчетов из используемых источников данных, которые основываются на данных, обновляемых ежедневно, охватывая множество бизнес-объектов.
В ходе проекта мы реализовали корпоративное хранилище данных на методологии Data Vault 2.0 и смогли обеспечить динамическую поддержку различных отчетов из используемых источников данных, которые основываются на данных, обновляемых ежедневно, охватывая множество бизнес-объектов.
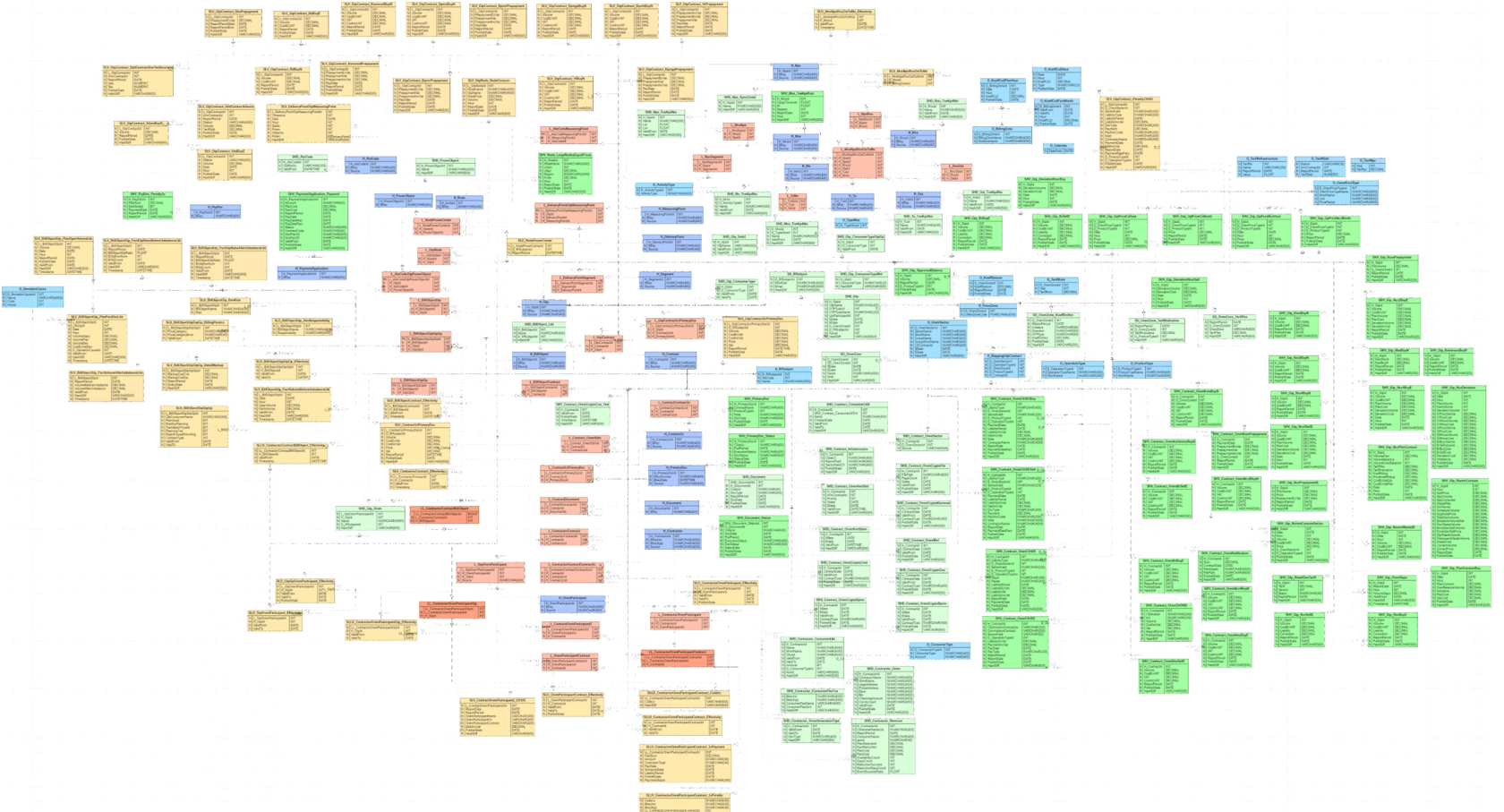
На схеме мы применили цветовое кодирование — способ визуально выделять разные типы сущностей в модели, который помогает архитекторам и аналитикам быстро «читать» модель.
На схеме сателлиты хабов и справочников выделены зеленым и имеют префиксы SD_ (Satellite Dictionary), SHD_ (Satellite hub description), SHV_ (Satellite hub value).
Сателиты ссылок используют префиксы SLD_ (Satellite link description), SLV_ (Satellite link value) и кодируются желтым цветом.
Таким образом, в результате реализации кейса Заказчик получил прозрачную аналитику, а команда — архитектуру, которая надежно выдерживает изменения источников. Кроме того, автоматизированный мониторинг оперативно уведомляет специалистов Conteq об изменениях, что обеспечивает быстрое реагирование на поставленные задачи.
- Хабы (Hubs) — синий, имеют префикс H_. Это центральные таблицы объектов, где хранятся бизнес-ключи.
- Справочники (Dictionaries) — голубой, имеют префикс D_. Описывают объекты без бизнес-сущностей, например календарь или справочник типов.
- Ссылки (Links) — красный. Таблицы, которые описывают связи между хабами использует светло-красный цвет и префикс L_, для связей между таблицами ссылок используется темно-красный цвет и префикс LL_.
- Сателлиты (Satellites) — желтый и зеленый. Хранят атрибуты и их историю изменений (например, адрес клиента или статус заказа).
На схеме сателлиты хабов и справочников выделены зеленым и имеют префиксы SD_ (Satellite Dictionary), SHD_ (Satellite hub description), SHV_ (Satellite hub value).
Сателиты ссылок используют префиксы SLD_ (Satellite link description), SLV_ (Satellite link value) и кодируются желтым цветом.
Таким образом, в результате реализации кейса Заказчик получил прозрачную аналитику, а команда — архитектуру, которая надежно выдерживает изменения источников. Кроме того, автоматизированный мониторинг оперативно уведомляет специалистов Conteq об изменениях, что обеспечивает быстрое реагирование на поставленные задачи.
Итог
Data Vault 2.0 — это зрелая архитектурная философия, которая сочетает в себе гибкость Agile, строгую структурированность и надежность в условиях реальных бизнес-процессов.
Для компаний, стремящихся к цифровой трансформации, Data Vault становится фундаментом, на котором строится вся аналитика — от отчетов до машинного обучения.
Для компаний, стремящихся к цифровой трансформации, Data Vault становится фундаментом, на котором строится вся аналитика — от отчетов до машинного обучения.
Cвяжитесь с нами сейчас — мы готовы ответить на ваши вопросы!